
Adobe just got hit with a lawsuit that could reshape how tech companies source AI training data. An Oregon author claims the software giant used pirated versions of her books to train its AI models without permission or payment.
The timing couldn’t be worse for Adobe. After years of pushing aggressive AI expansion, the company now faces accusations that mirror problems plaguing the entire tech industry. And this case involves datasets that have already triggered multiple lawsuits against other major players.
The Books3 Problem Strikes Again
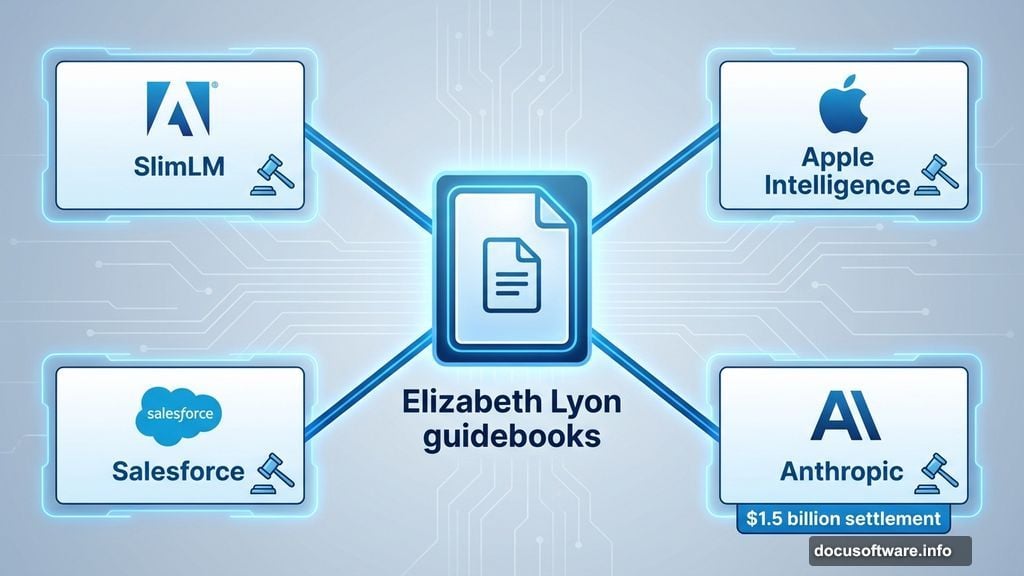
Elizabeth Lyon, who writes guidebooks for non-fiction authors, filed the proposed class-action in December 2025. Her claim centers on SlimLM, Adobe’s small language model designed for document tasks on mobile devices.
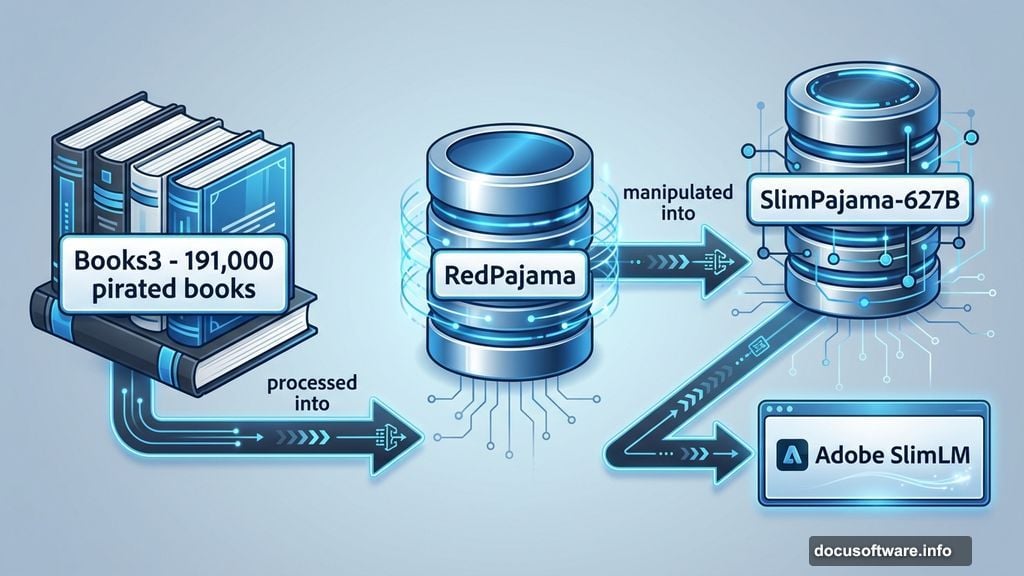
Here’s where it gets messy. Adobe says SlimLM was trained on SlimPajama-627B, an open-source dataset released by Cerebras in June 2023. But Lyon’s lawsuit argues that SlimPajama contains a processed version of Books3, a notorious collection of 191,000 pirated books.
So the chain goes like this: Books3 fed into RedPajama, which got manipulated into SlimPajama, which then trained Adobe’s AI model. Lyon claims her copyrighted work ended up in that pipeline without consent, credit, or compensation.
Books3 has become a recurring nightmare for AI companies. The dataset keeps appearing in lawsuits because it’s convenient, massive, and completely unauthorized. Tech firms apparently decided copying was easier than licensing.
Adobe Joins Growing List of Defendants
Adobe isn’t alone in facing these accusations. The Books3 and RedPajama datasets have triggered a wave of similar lawsuits across Silicon Valley.
Apple got sued in September 2025 over claims it used the same materials to train Apple Intelligence. Salesforce faced nearly identical allegations in October. Meanwhile, Anthropic agreed to pay authors $1.5 billion that same September after being accused of using pirated books for its Claude chatbot.
That Anthropic settlement marked a potential turning point. Instead of fighting endlessly, the company cut a massive check. Other firms watching these cases now understand the stakes.
But Adobe’s situation carries extra weight because of SlimLM’s specific purpose. This isn’t a general chatbot. It’s designed to help users with documents on mobile devices. The irony? An AI tool meant to assist with writing might have been trained on stolen writing.
The Pretraining Dataset Defense Falls Apart
Adobe’s defense relies on claiming SlimPajama was an open-source dataset. Technically true. But that defense ignores how the data got there.
Open-source doesn’t mean legitimate. A dataset can be freely available while still containing pirated content. SlimPajama being public doesn’t erase the alleged theft one layer down in RedPajama, which incorporated Books3.
Plus, Adobe should have done due diligence. Major corporations can’t just grab convenient datasets without checking their origins. That’s like buying a suspiciously cheap laptop from a guy in an alley and acting shocked when it turns out to be stolen.
Lyon’s lawsuit argues Adobe knew or should have known about Books3’s presence in the training data. The Books3 controversy wasn’t secret. It’s been discussed extensively in AI circles and previous legal cases.
So Adobe’s position boils down to: “We used a derivative of a derivative of pirated books, but we didn’t technically touch the pirated books ourselves.” Courts may not find that distinction meaningful.
What This Means for AI Development
These lawsuits reveal a fundamental problem with AI training practices. Companies need massive datasets, but legitimate content isn’t free or easy to obtain. So they’ve relied on scraped, pirated, or questionably sourced materials.
That worked fine when nobody was paying attention. Now authors, publishers, and content creators are fighting back with serious legal muscle. The Anthropic settlement proved these cases can succeed and force massive payouts.
For Adobe specifically, this could damage their AI strategy just as they’re trying to compete with OpenAI, Google, and other AI leaders. Firefly and related products depend on customer trust. Accusations of using stolen training data undermine that trust completely.
Meanwhile, other tech companies are watching nervously. If Adobe loses or settles, it establishes precedent. More authors will file similar suits against other firms using questionable datasets.
The Bigger Question Nobody Wants to Answer
Here’s what really bugs me about these cases. Tech companies had options. They could have licensed content legally. They could have created synthetic training data. They could have used truly open materials.
Instead, they chose convenience over ethics. Books3 existed, it was comprehensive, and nobody stopped them from using it. So they did, consequences be damned.
Now we’re watching the consequences play out in real time. Adobe joins a growing list of defendants. Authors are organizing class-actions. Settlement costs are climbing into billions. And the AI industry’s dirty secret about training data is becoming public knowledge.
The solutions exist. Companies can pay content creators fairly for training data. They can develop better synthetic alternatives. They can build models that respect copyright from the start.
But that requires admitting past practices were wrong and spending money to fix them. Don’t hold your breath waiting for tech companies to volunteer for either option.